
How to build your own offline Google search
A search engine for your data and the way you think

I am going to preface this with the fact that I am not an expert in building search engines. I am, however, someone who has spent an incredible amount of time thinking about saving and searching for information. I have some ideas that I want to share.
At its core, Google Search has two things: save and search. When you open up google.com, you only see the search bar. Behind the scenes, there is an immense amount of work that is needed to have meaningful results show up when you search. Google manages bots whose sole purpose is to find links on web pages and go to those links. And the bots, or “web crawlers”, just keep doing this over and over, only ever _maybe_ stopping if a website has asked politely not to (with a robots.txt file). When Google finds new links, it will process them to create an efficient lookup, allowing them to respond to your search across the entire Internet in milliseconds.
Save
What I want to point out here is that Google operates on the scale of the entire Internet. To come up with relevant search results when someone searches "banana phone" is a really difficult problem to solve. Think about this problem scaled down to what I like to call "your internet". Your Internet is one that is comprised of only the websites that you have been on, and maybe sometimes, if you want it to, websites n links deeper. The problem of saving and searching becomes different. You can build out your Internet, theoretically, by simply browsing normally. Every page you visit or bookmark is exactly what a web crawling bot would do, but the act of you having personally visited them increases their relevancy to you. Any pages that you visit are inventoried and eventually considered when you want to figure out where you have seen "banana phone" before.
You might ask; “But web browsers already have "history" I can search?” I don't know about you, but I rarely find that search helpful at all, unless I am looking for a tab I recently closed. The reason this search is not that helpful is because unlike the Google search bar, the browser history search does not make use of “indexing”.

Indexing is very important when it comes to searching. Indexing groups similar things together. The relationship between items can be more concrete than others. Normally with Google searches, indexes that are being referred to are generated based on semantic relationships between words. Google also offers access to more concrete indexes with filters such as "site:example.com", called "dorks" (very helpful for finding interesting things), which will limit the search results to only pages that come from the domain "example.com". The combination of indexes can lead to very powerful retrieval methods, but building a system that will generate these indexes can be quite complex.
When you index information, you are taking a step away from the source of truth. The source of truth for a webpage is whatever content is returned when you visit its URL. Once you crawl this page and download the content, your content is now one step away from the source of truth. If the webpage gets updated, someone searching for a page based on the new content would not find it. This is remediated by keeping track of the content's originating URL as well as the last time it was collected so that we can know when to schedule the next time to get the content. But the complexity does not stop there. A web page has a lot of HTML, JS, and CSS that a user doesn't want to have considered when searching, so we are going to have to clean that up, again taking a step from the content's source of truth. Collecting the page, cleaning it up, processing it to collect metadata of interest like the author, published date, recipe, tables, or any other that might be of interest are all steps that are valuable for providing better search results.

The entire point of an index is so that you can refer to information without needing to know the exact information, but rather some attribute about the data. What I find interesting about indexes is that the more effective ones are more personal than anything. For example, I might be looking for an answer to a coding question, and I come across someone's blog post and I am surprised to find myself looking at a purple zebra. The author of the post has included an image of a purple zebra, an image completely unrelated to the content of the post. Assuming this post is well written, I am probably going to refer back to it. If I try to find that specific post using the same search query as before, it is very possible that the page will have been lost in the sands of time. But that image of a purple zebra is seared into my mind. What if my personal Google indexed images on that page and I had a follow up step of using AI to generate image tags? If I now search my coding question along with "zebra", odds are I am going to find what I am looking for. Services like Pinterest are used religiously for people building manual indexes, and new services such as MyMind will now do this automatically.
In terms of the first step of saving data, this pretty much sums up the steps needed. You can go crazy with the technical details of how to process and store this data, but for your own Google, pretty basic tech is going to get you pretty far. Storing content into an sqlite database is dead simple to use and will be able to hold a good deal of data before you need to scale up, and migration is always an option.
Search
Once we have our data indexed, we are going to want a way to search these indexes. Having the simplicity of a search box is nice, but if we are building our own Google, we can define whatever filters we want. Our "advanced" search can tap into the power of our indexes and go well beyond "site:example.com" especially considering the possibility of using indexes generated from a fine-tuned LLM model, more on that later.
For generating search results, it seems the best approach is to use a hybrid approach with a dense and sparse algorithm.
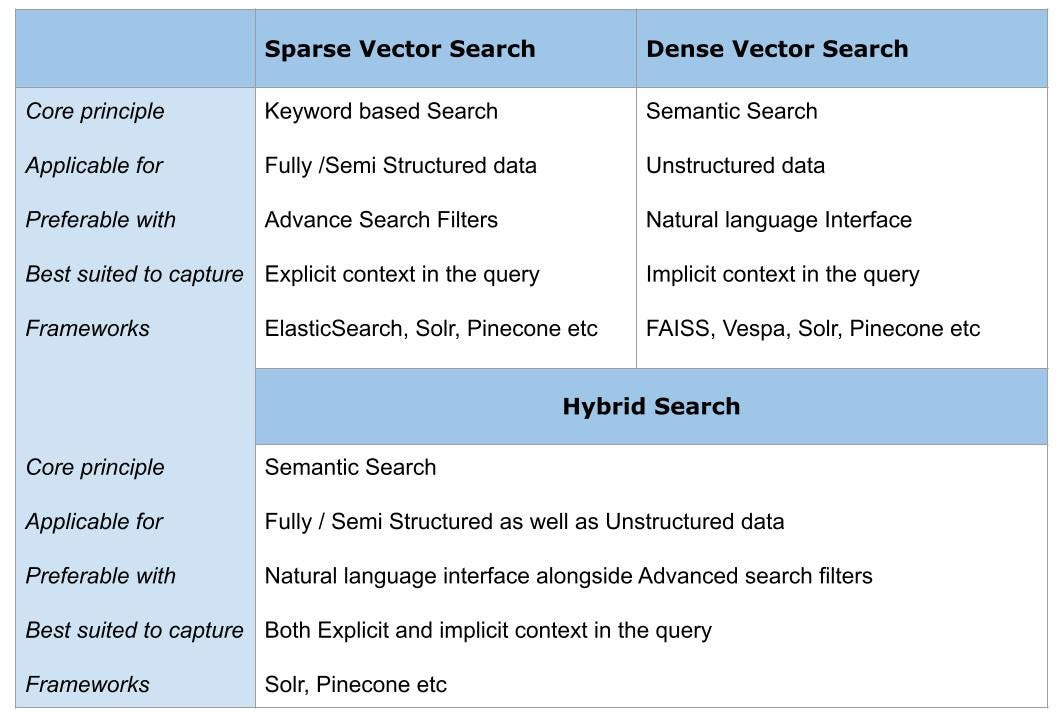
Sparse vs dense is in reference to how many zeros are present in the vector that is used to index the content. Sparse means that there are more zeros, dense means there are less. A sparse algorithm is rooted in pretty simple statistics vs dense comes from a fine tuned ML model, which is more or less just a computer coming up with its own statistical algorithm for the content it has seen. TF-IDF is a well documented sparse algorithm that is helpful for understanding nuts and bolts of this space and FAISS is helpful for understand sparse vectors. There has been a lot of attention on the dense vector similarity search, but the tried and true sparse algorithms are still relevant, for now.
What I think is cool about building our own Google is that we don't have to stop at getting back a list of results from our search. We can take these results and then dispatch an agent, whose code could range from a grep to an LLM prompt, which goes through the returned content, byte by byte, and tries to find more specific information, or reason about the results for us. If we wanted to see example usages of a function from a library, our agent could clone the GitHub repo that we had visited previously, pull it down, parse the AST and provide high-confidence, specific detail about how to write the code we want.
Feedback
There is another part beyond the basics of save and search which is critical to how Google works which greatly improves how the search works, and that is feedback. You don't see upvote or downvote buttons on the Google search results page, but Google doesn't need that to know which results helped you more than others. If you haven't seen it yet, Chrome has added a feature called Journeys which is located near History. A Journey is collection of links starting from your first Google search and ending once you found your answer from the search results. Google knows everything you do when you are on google.com, as well as anything you do off of it for that matter. They know how long you spend scrolling through the results, what you click on, follow up things you search for. They have it all. All of this data, paired with the identity that Google has deduced about you (age, geolocation, etc.) are factored into the results you end up seeing.
For our personal Google, we could implement this creepy algorithm to improve our own search results, but there is something that I think could be much more impactful. The Internet was originally considered to be a connected set of documents that people would annotate so that others could see other people's opinions about content, or enhance the content with links to even more documents. Our web browsers have delivered pretty well on the interconnected document part, but not so much on the annotation part. We rely on annotation systems provided by pretty much just comment sections from large services like Facebook, YouTube, Reddit, and countless blogs and the forgotten guest books. All of these annotations are subjected to the ever aging service they are hosted on and the waning days before they are forgotten about and replaced by what is new. I believe the things that we come across when using the Internet and our impressions of those things are own. The data has already been transferred to our computers, why don’t we have the option to save it for later?!
Let’s make it happen
I have been thinking about this for a while, and I think that there is big monetary opportunity here for people to write code and generate helpful indexes that people could use to build their own Google. Maybe you could build these indexes locally, or maybe you connect with your friend’s indexes. In the age of AI, data is going to be everything, and those who can collect and generate high quality data are going to reign supreme. Encouraging people to build these data sets is going to provide immense value. Additionally, having people collaborate and share their Internet with others is really the only way that I see that we are going to be able to survive the inevitable onslaught of AI generated content. If you are interested in seeing the work that I have done so far in building this, you can check out LunaBrain. Still very much a work in progress, but I would love to hear from you about your thoughts on this space!
Great idea!